导出sql数据库数据的方法有几种方式
![]() 发布网友
发布时间:2022-04-23 08:24
发布网友
发布时间:2022-04-23 08:24
共2个回答
![]() 懂视网
时间:2022-05-01 22:39
懂视网
时间:2022-05-01 22:39
SQLTask+Tunnel
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
private static final String accessId = "userAccessId";
private static final String accessKey = "userAccessKey";
private static final String endPoint = "http://service.odps.aliyun.com/api";
private static final String project = "userProject";
private static final String sql = "userSQL";
private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字
private static final Odps odps = getOdps();
public static void main(String[] args) {
System.out.println(table);
runSql();
tunnel();
}
/*
* 把SQLTask的结果下载过来
* */
private static void tunnel() {
TableTunnel tunnel = new TableTunnel(odps);
try {
DownloadSession downloadSession = tunnel.createDownloadSession(
project, table);
System.out.println("Session Status is : "
+ downloadSession.getStatus().toString());
long count = downloadSession.getRecordCount();
System.out.println("RecordCount is: " + count);
RecordReader recordReader = downloadSession.openRecordReader(0,
count);
Record record;
while ((record = recordReader.read()) != null) {
consumeRecord(record, downloadSession.getSchema());
}
recordReader.close();
} catch (TunnelException e) {
e.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
/*
* 保存这条数据
* 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。
* */
private static void consumeRecord(Record record, TableSchema schema) {
System.out.println(record.getString("username")+","+record.getBigint("cnt"));
}
/*
* 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载
* 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间
* */
private static void runSql() {
Instance i;
StringBuilder sb = new StringBuilder("Create Table ").append(table)
.append(" lifecycle 1 as ").append(sql);
try {
System.out.println(sb.toString());
i = SQLTask.run(getOdps(), sb.toString());
i.waitForSuccess();
} catch (OdpsException e) {
e.printStackTrace();
}
}
/*
* 初始化MaxCompute(原ODPS)的连接信息
* */
private static Odps getOdps() {
Account account = new AliyunAccount(accessId, accessKey);
Odps odps = new Odps(account);
odps.setEndpoint(endPoint);
odps.setDefaultProject(project);
return odps;
}
工具实现
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
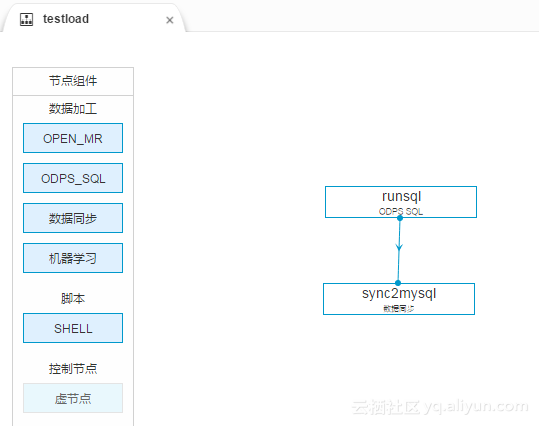
里面配置的SQL作业和同步作业的配置如图:
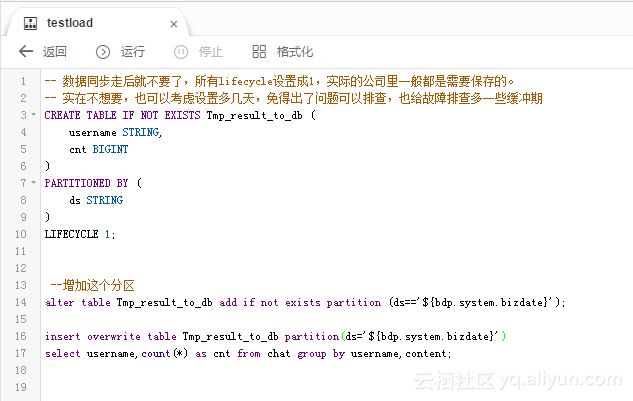
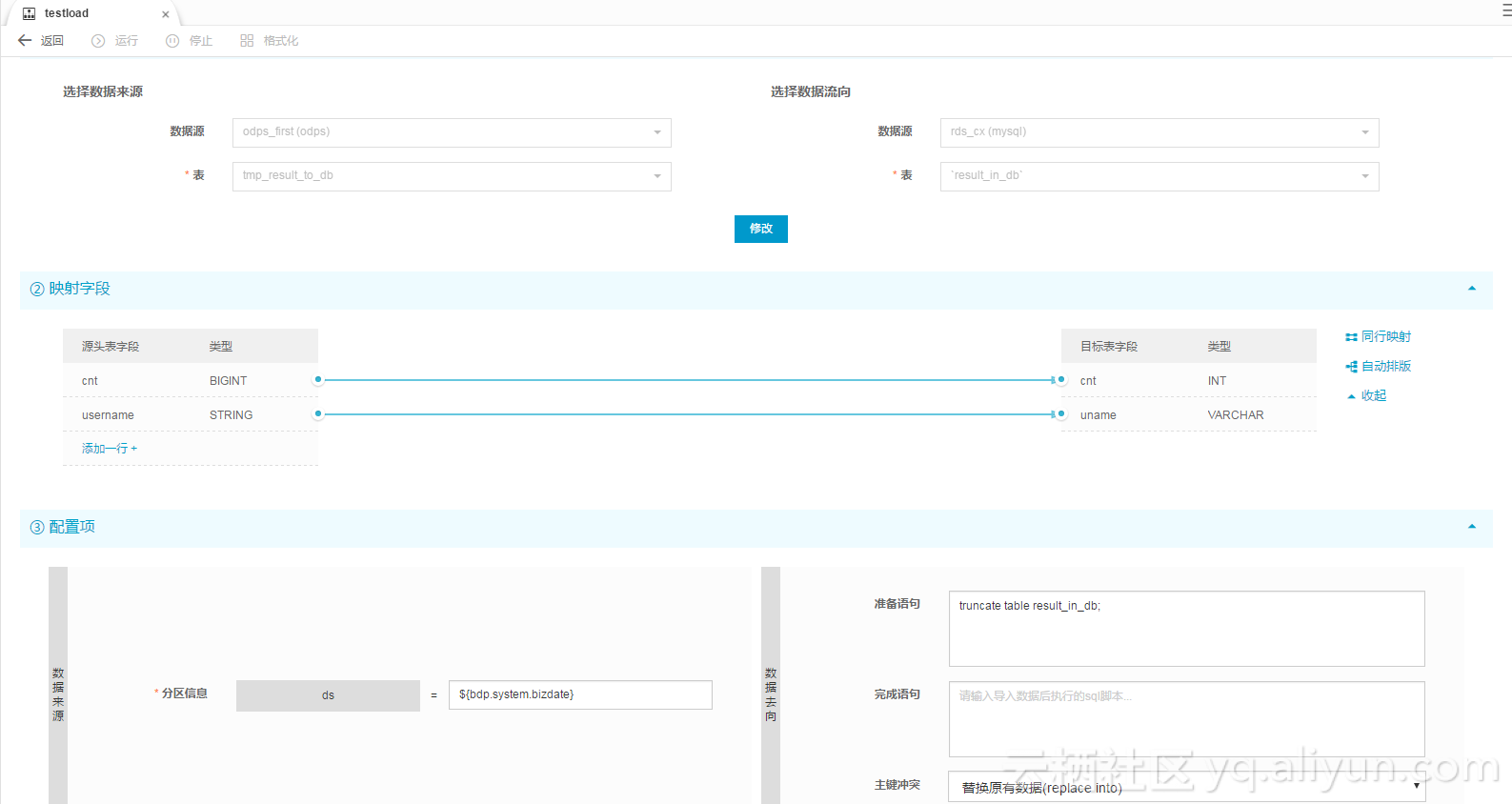
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer -
任务启动时刻 : 2016-12-17 23:43:34
任务结束时刻 : 2016-12-17 23:43:46
任务总计耗时 : 11s
任务平均流量 : 31.36KB/s
记录写入速度 : 1668rec/s
读出记录总数 : 16689
读写失败总数 : 0
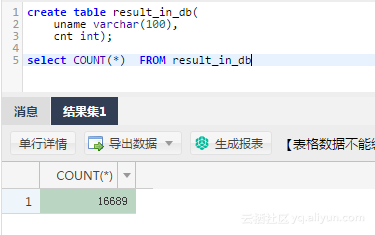
到mysql里查一下,数据也进去了。
总结
阅读原文请点击
导出SQL运行结果的方法总结
标签:container 参考 工作流 product 存在 dom idt 开发 put
![]() 热心网友
时间:2022-05-01 19:47
热心网友
时间:2022-05-01 19:47
导入向导,微软提供了多种数据源驱动,包括SQL Server Native Cliant, OLE DB For Oracle,Flat File Source,Access,Excel,XML等,基本上可以满足系统开发的需求.
同样导出向导也有同样多的目的源驱动,可以把数据导入到不同的目的源.
对数据库管理人员来说这种方式简单容易操作,导入时SQL Server也会帮你建立相同结构的Table.
2. 用.NET的代码实现(比如有一个txt或是excel的档案,到读取到DB中)
2.1 最为常见的就是循环读取txt的内容,然后一条一条的塞入到Table中.这里不再赘述.
2.2 集合整体读取,使用OLEDB驱动.
代码如下:
代码
string strOLEDBConnect = @"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=D:\1\;Extended Properties='text;HDR=Yes;FMT=Delimited'";
OleDbConnection conn = new OleDbConnection(strOLEDBConnect);
conn.Open();
SQLstmt = "select * from 1.txt";//读取.txt中的数据
DataTable dt=new DataTable();
OleDbDataAdapter da = new OleDbDataAdapter(SQLstmt, conn);
da.Fill(dt);//在DataSet的指定范围中添加或刷新行以匹配使用DataSet、DataTable 和IDataReader 名称的数据源中的行。
if(dt.Rows.Count>0)
foreach(DataRow dr in dt.Rows)
{
SQLstmt = "insert into MyTable values('" + dr..."
3.BCP,可以用作大容量的数据导入导出,也可以配合来使用.
语法:
代码
bcp {[[database_name.][schema].]{table_name | view_name} | "query"}
{in | out | queryout | format} data_file
[-mmax_errors] [-fformat_file] [-x] [-eerr_file]
[-Ffirst_row] [-Llast_row] [-bbatch_size]
[-ddatabase_name] [-n] [-c] [-N] [-w] [-V (70 | 80 | 90 )]
[-q] [-C { ACP | OEM | RAW | code_page } ] [-tfield_term]
[-rrow_term] [-iinput_file] [-ooutput_file] [-apacket_size]
[-S [server_name[\instance_name]]] [-Ulogin_id] [-Ppassword]
[-T] [-v] [-R] [-k] [-E] [-h"hint [,...n]"]
请注意数据导入导出的方向参数:in,out,queryout
如:
如:
4.BULK INSERT. T-SQL的命令,允许直接导入数据
语法:
BULK INSERT
[ database_name. [ schema_name ] . | schema_name. ] [ table_name | view_name ]
FROM 'data_file'
[ WITH
(
[ [ , ] BATCHSIZE =batch_size ]
[ [ , ] CHECK_CONSTRAINTS ]
[ [ , ] CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ [ , ] DATAFILETYPE =
{ 'char' | 'native'| 'widechar' | 'widenative' } ]
[ [ , ] FIELDTERMINATOR = 'field_terminator' ]
[ [ , ] FIRSTROW = first_row ]
[ [ , ] FIRE_TRIGGERS ]
[ [ , ] FORMATFILE ='format_file_path' ]
[ [ , ] KEEPIDENTITY ]
[ [ , ] KEEPNULLS ]
[ [ , ] KILOBYTES_PER_BATCH =kilobytes_per_batch ]
[ [ , ] LASTROW =last_row ]
[ [ , ] MAXERRORS =max_errors ]
[ [ , ] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ]
[ [ , ] ROWS_PER_BATCH =rows_per_batch ]
[ [ , ] ROWTERMINATOR ='row_terminator' ]
[ [ , ] TABLOCK ]
[ [ , ] ERRORFILE ='file_name' ]
)]
重要参数:
FIELDTERMINATOR,字段分隔符
FIRSTROW:第一个数据行
ROWTERMINATOR:行终结符
如:
BULK INSERT dbo.ImportTest
FROM 'C:\ImportData.txt'
WITH ( FIELDTERMINATOR =',', FIRSTROW = 2 )
5. OPENROWSET也是T-SQL的命令,包含有DB连接的信息和其它导入方法不同的是,OPENROWSET可以作为一个目标表参与INSERT,UPDATE,DELETE操作.
语法:
OPENROWSET
( { 'provider_name', { 'datasource';'user_id';'password'
| 'provider_string' }
, { [ catalog. ] [ schema. ] object
| 'query'
}
| BULK 'data_file',
{ FORMATFILE ='format_file_path' [ <bulk_options> ]
| SINGLE_BLOB | SINGLE_CLOB | SINGLE_NCLOB }
} )<bulk_options> ::=
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ERRORFILE ='file_name' ]
[ , FIRSTROW = first_row ]
[ , LASTROW = last_row ]
[ , MAXERRORS = maximum_errors ]
[ , ROWS_PER_BATCH =rows_per_batch ]
如:
INSERT INTO dbo.ImportTest
SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\ImportData.xls', 'SELECT * FROM [Sheet1$]') WHERE A1 IS NOT NULL
6.OPENDATASOURCE
语法:
OPENDATASOURCE ( provider_name,init_string )
如:
INSERT INTO dbo.ImportTest
SELECT * FROM OPENDATASOURCE('Microsoft.Jet.OLEDB.4.0',
'Data Source=C:\ImportData.xls;Extended Properties=Excel 8.0')...[Sheet1$]
7.OPENQUERY.是在linked server的基础上执行的查询.所以执行之前必须先建立好link server.OPENQUERY的结果集可以作为一个table参与DML的操作.
语法:
OPENQUERY (linked_server ,'query')
如:
EXEC sp_addlinkedserver 'ImportData',
'Jet 4.0', 'Microsoft.Jet.OLEDB.4.0',
'C:\ImportData.xls',
NULL,
'Excel 8.0'
GO
INSERT INTO dbo.ImportTest
SELECT *
FROM OPENQUERY(ImportData, 'SELECT * FROM [Sheet1$]')
